CloudFront

CloudFront - Core Components
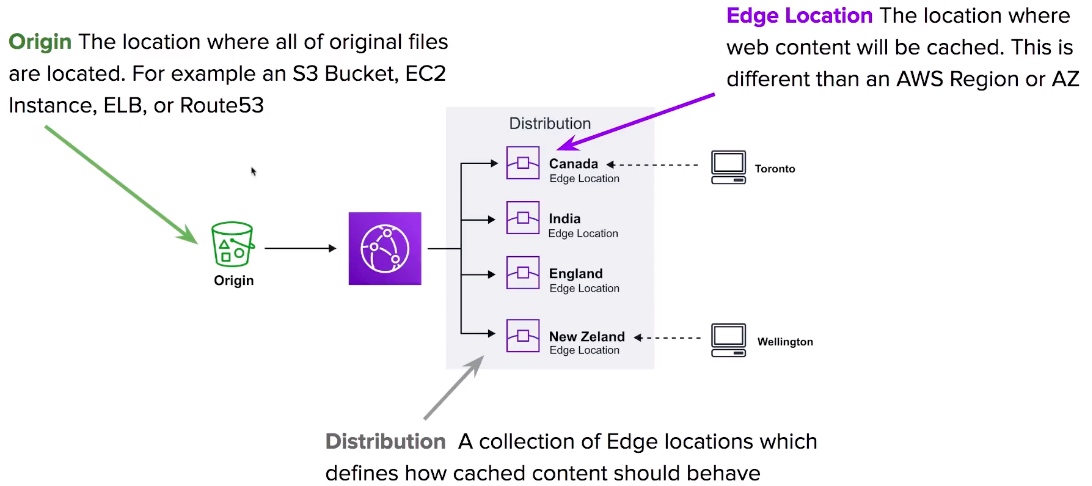
CloudFront - Distributions

CloudFront - Lamdba@Edge

CloudFront - Protection

CloudFront - Cheatsheet
- CloudFront is a CDN (Content Distribution Network). It makes website load fast by serving cached content that is nearby.
- CloudFront distributes cached copy at Edge Locations.
- Edge Locations aren’t just not read-only, you can write to them eg. PUT objects.
- TTL (Time to live) defines how how long until the cache expires (refreshes cache)
- When you invalidate your cache, you are forcing it to immediately expire (refreshes cached data)
- Refreshing the cache costs money because of transfer costs to update Edge Locations.
- Origin is the address of where the original copies of your files reside eg. S3, EC2, ELB, Route53.
- Distribution defines a collection of Edge Locations and behaviour on how it should handle your cached content.
- Distributions has 2 Types: Web Distribution (static website content) RTMP (streaming media)
- Origin Identity Access (OAI) is used access private S3 buckets
- Access to cached content can be protected via Signed Urls or Signed Cookies.
- Lambda@Edge allows you to pass each request through a Lambda to change the behaviour of the response.
Relational Database Service (RDS)

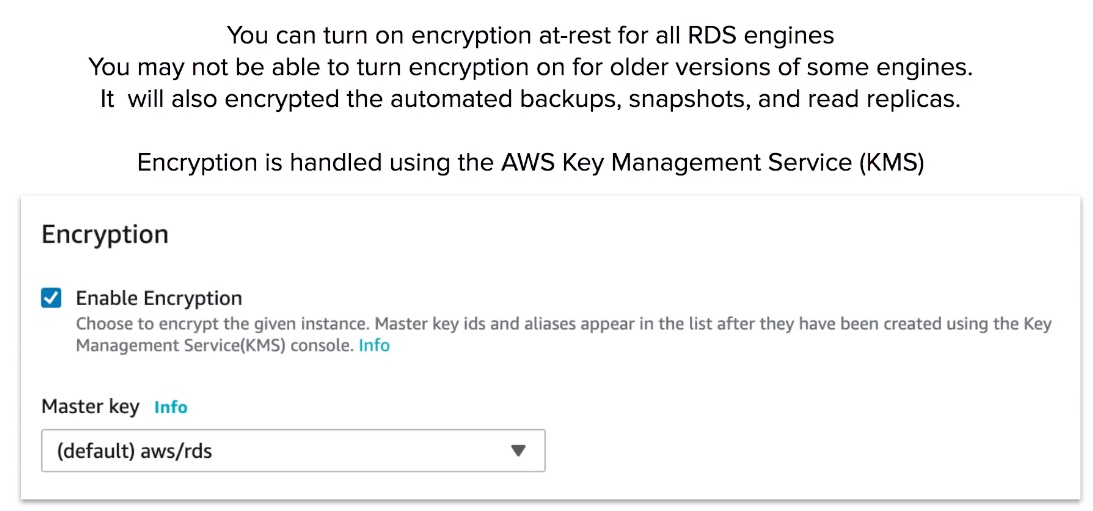
RDS - Encryption
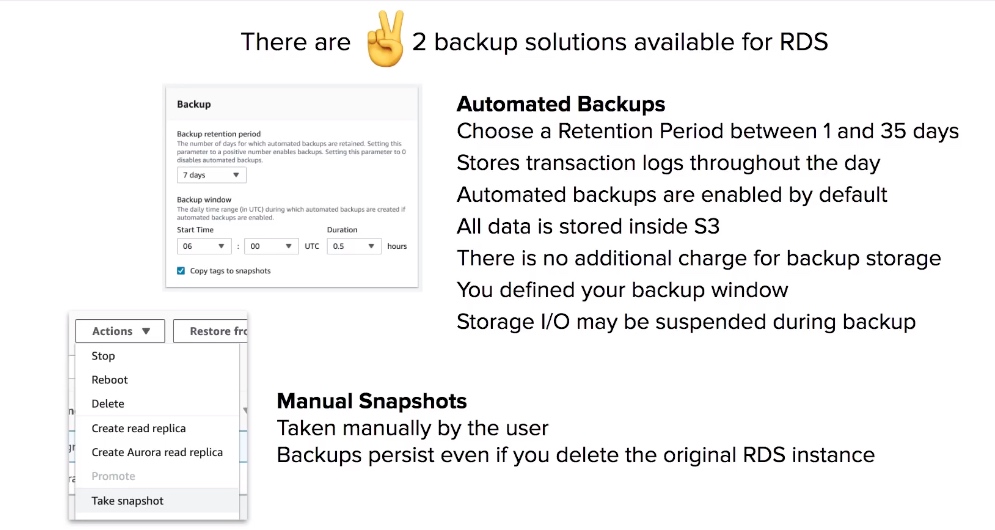
RDS - Backup
RDS - Restoring Backup

RDS - Multi AZ

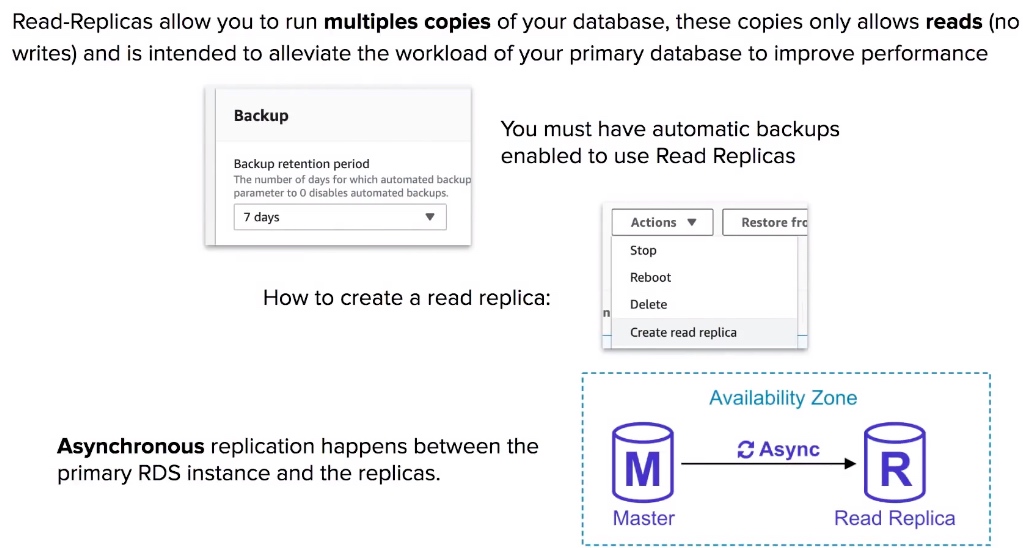
RDS - Read Replicas

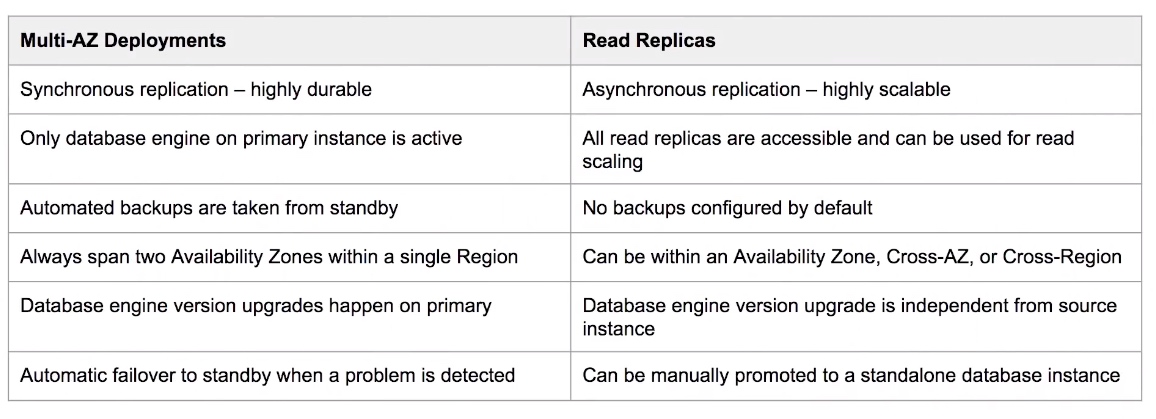
RDS - Multi-AZ vs Read Replicas
RDS CheatSheet
- Relational Database Service (RDS) is the AWS Solution for relational databases.
- RDS instances are managed by AWS, You cannot SSH into the VM running the database.
- There are 6 relational database options currently available on AWS, Aurora, MySQL, MariaDB, Postgres, Oracle, Microsoft SQL Server.
- Multi-AZ is an option you can turn on which makes an exact copy of your database in another AZ that is only standby.
- For Multi-AZ AWS automatically synchronizes changes in the database over to the standby copy.
- Multi-AZ has Automatic Failover protection if one AZ goes down failover will occur and the standby slave will be promoted to master.
- Read-Replicas allow you to run multiples copies of your database, these copies only allows reads (no writes) and is intended to alleviate the workload of your primary database to improve performance.
- Read-Replicas use Asynchronous replication.
- You must have automatic backups enabled to use Read Replicas.
- You can have upto 5 read replicas.
- You can combine Read Replicas with Multi-AZ.
- You can have Read Replicas in another Region (Cross-Region Read Replicas).
- Replicas can be promoted to their own database, but this breaks replication.
- You can have Replicas of Read Replicas.
- RDS has 2 backup solutions: Automated Backups and Database Snapshots.
- Automated Backups, you choose a retention period between 1 and 35 days, There is no additional cost for backup storage, you define your backup window.
- Manual Snapshots, you manually create backups, if you delete your primary the manual snapshots will still exist and can be restored
- When you restore an instance it will create a new database. You just need to delete your old database and point traffic to new restored database.
- You can turn on encryption at-rest for RDS via KMS.
Aurora

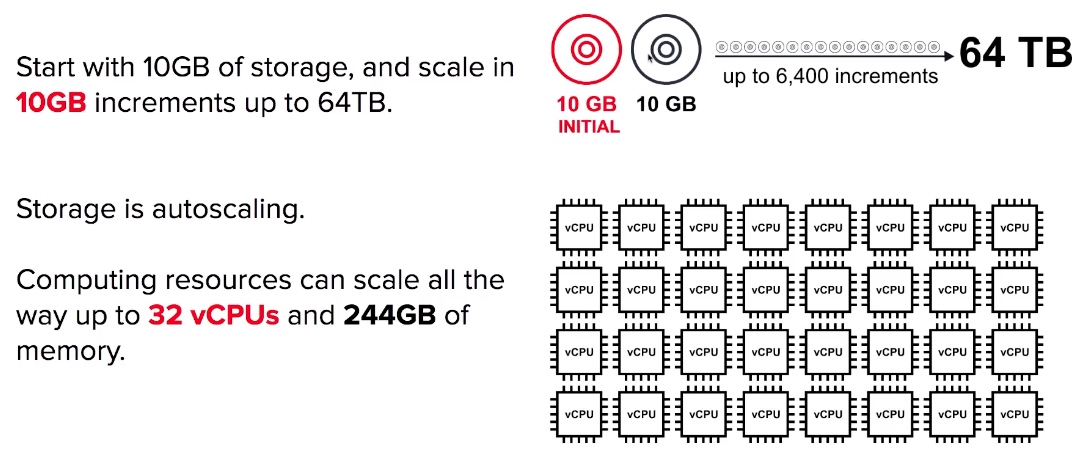
Aurora - Scaling
Aurora - Availability
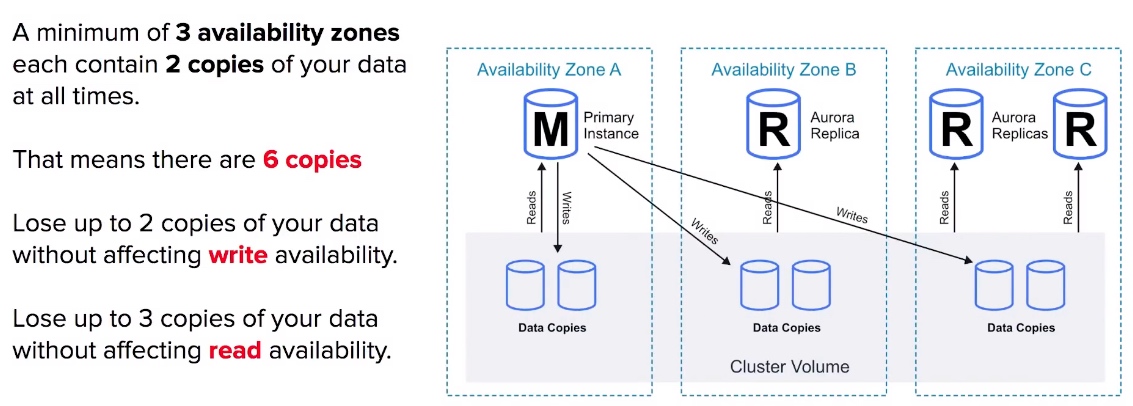
Aurora - Fault Tolerance and Durability
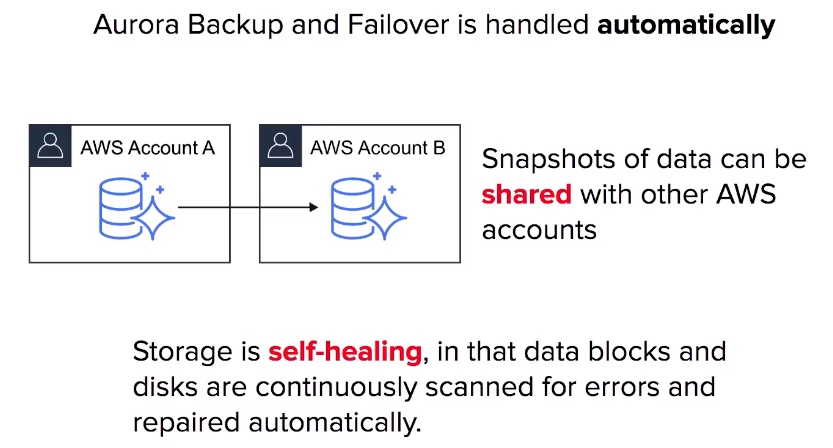
Aurora - Replicas
Aurora - Serverless
Aurora CheatSheet
- When you need a fully-managed Postgres or MySQL database that needs to scale, automatic backups, high availability and fault tolerance think Aurora.
- Aurora can run MySQL or Postgres database engines.
- Aurora MySQL is 5x faster over regular MySQL.
- Aurora Postgres is 3x faster over regular Postgres.
- Aurora is 1⁄10 the cost over its competitors with similar performance and availability options.
- Aurora replicates 6 copies for your database across 3 availability zones.
- Aurora is allowed up to 15 Aurora Replicas.
- An Aurora database can span multiple regions via Aurora Global Database.
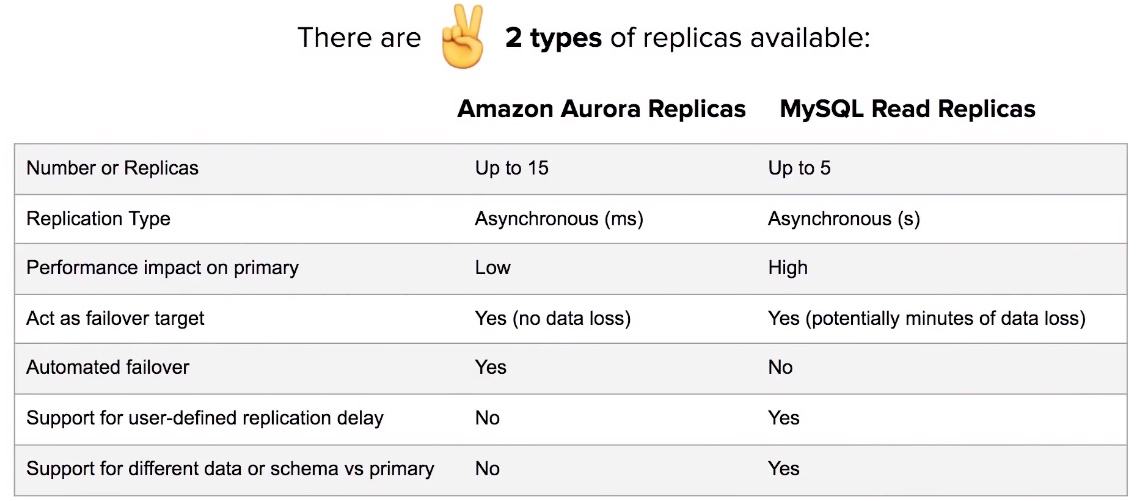
- Aurora Serverless allows you to stop and start Aurora and scale automatically while keeping costs low.
- Aurora Serverless is ideal for new projects or projects with infrequent database usage.
Amazon Redshift

Data Warehouse
Redshift - Use Case
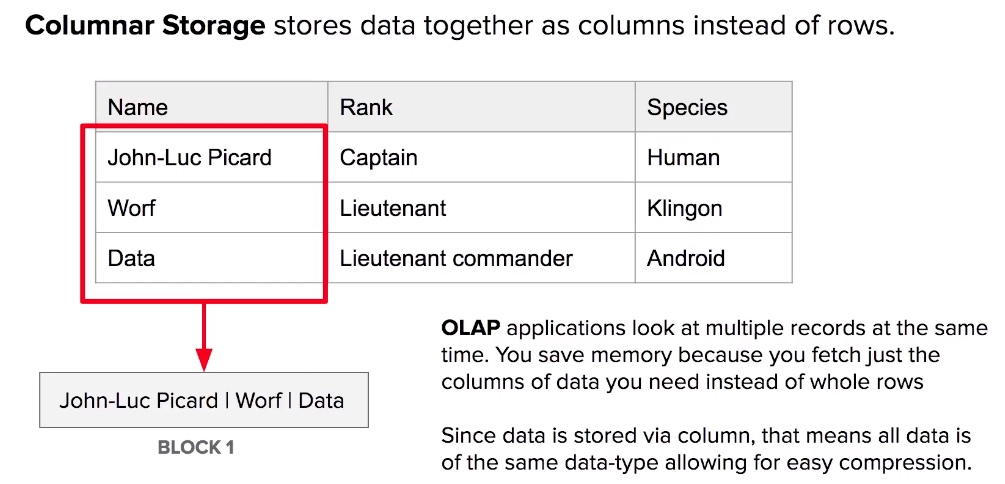
Redshift - Columnar Storage
Redshift - Configurations

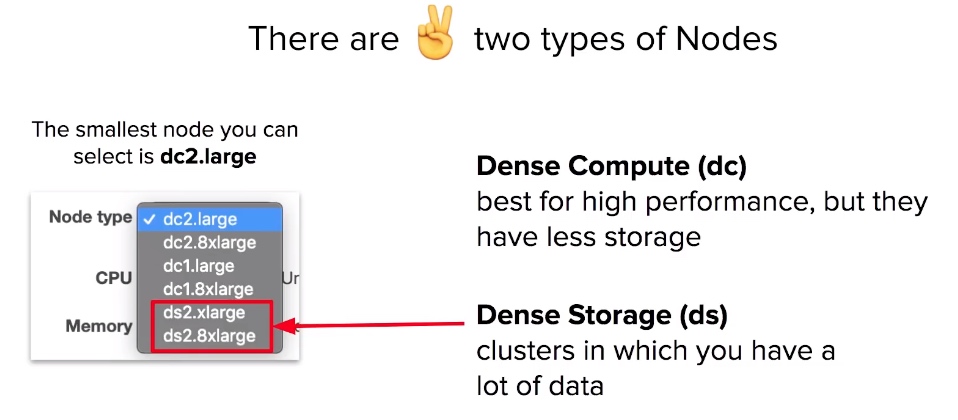
Redshift - Node Types and Sizes
Redshift - Compression
- Redshift uses multiple compression techniques to achieve significant compression relative to traditional relational data stores.
- Similar data is stored sequentially on disk.
- Does not require indexes or materialized views, which saves a lot of space compared to traditional systems.
- When loading data to an empty table, data is sampled and the most appropriate compression scheme is selected automatically.
Redshift - Processing
Redshift - Backups
Redshift - Billing
Compute Node Hours
- The total number of hours ran across all nodes in the billing period.
- Billed for 1 unit per node, per hour.
- Not charged for leader node hours, only compute notes incur charges.
Backup
- Backups are stored on S3 and you are billed the S3 storage fees
Data Transfer
- Billed for Only transfers within a VPC, not outside of it.
Redshift - Security

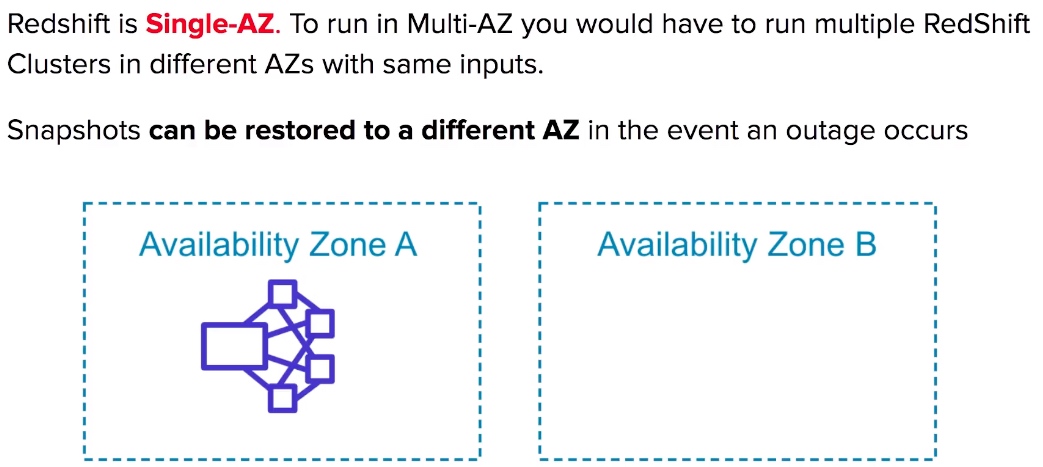
Redshift -Availability
Redshift CheatSheet
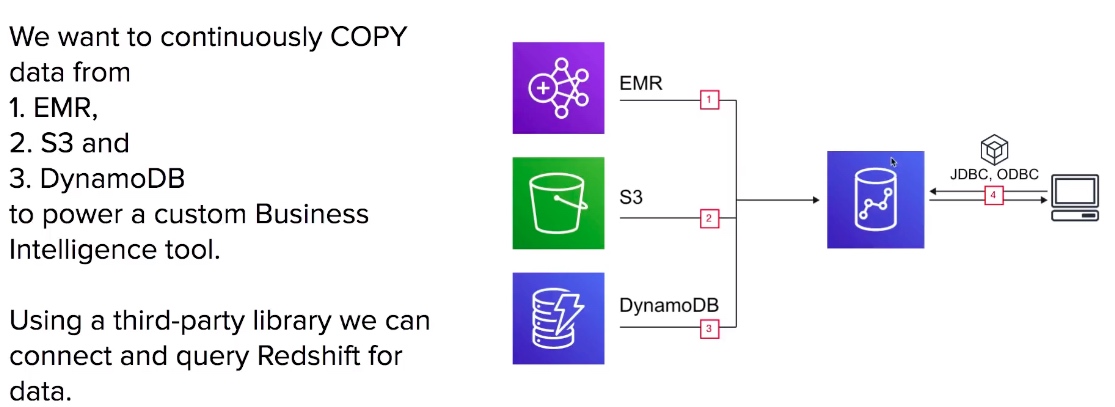
- Data can be loaded from S3, EMR, DynamoDB, or multiple data sources on remote hosts.
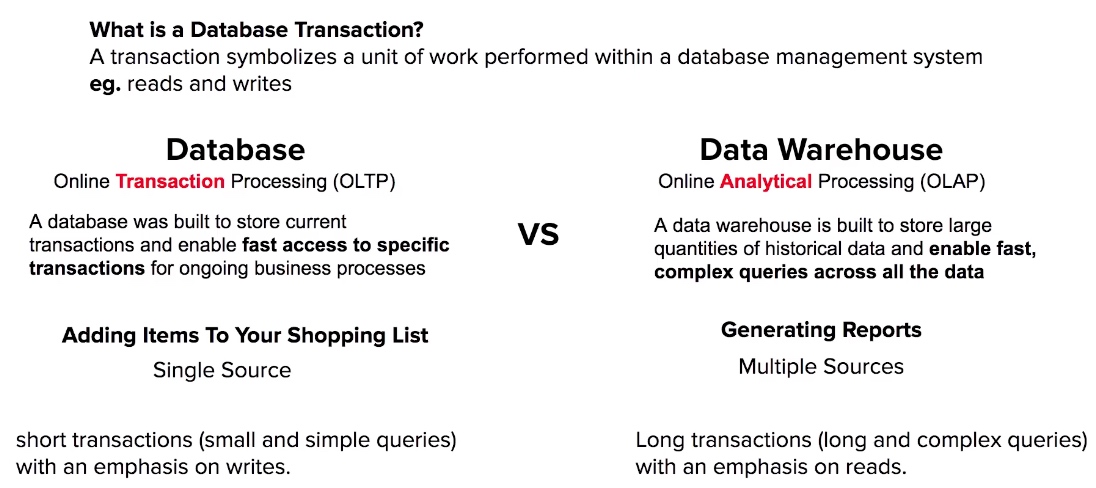
- Redshift is Columnar Store database which can SQL-like queries and is an OLAR.
- Redshift can handle petabytes worth of data. Redshift is for Data Warehousing.
- Redshift most common use case is Business Intelligence.
- Redshift can only run in a 1 availability zone (Single-AZ)
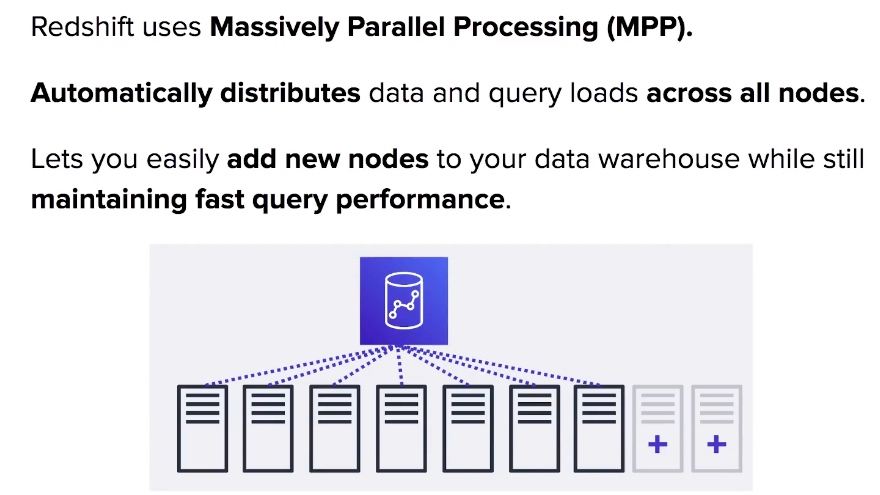
- Redshift can run via a single node or multi-node (clusters)
- A single node is 160 GB in size.
- A multi-node is comprised of a leader node and multiple compute nodes.
- You are bill per hour for each node (excluding leader node in multi-node)
- You are not billed for the leader node.
- You can have up to 128 compute nodes.
- Redshift has two kinds of Node Type Dense Compute and Dense Storage.
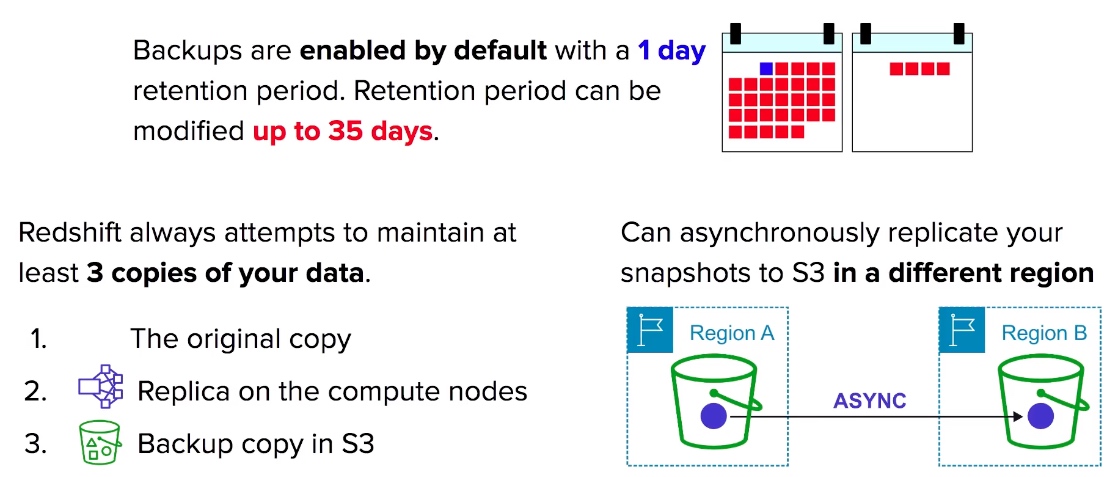
- Redshift attempts to backup 3 copies of your data, the original, on compute node and on S3.
- Similar data is stored on disk sequentially for faster reads.
- Redshift database can be encrypted via KMS or CloudHSM.
- Backup Retention is default to 1 day and can be increase to maximum of 35 days.
- Redshift can asynchronously back up your snapshot to Another Region delivered to S3.
- Redshift uses Massively Parallel Processing (MPP) to distribute queries and data across all loads.
- In the case of empty table, when importing Redshift will sample data to create a schema.
DynamoDB


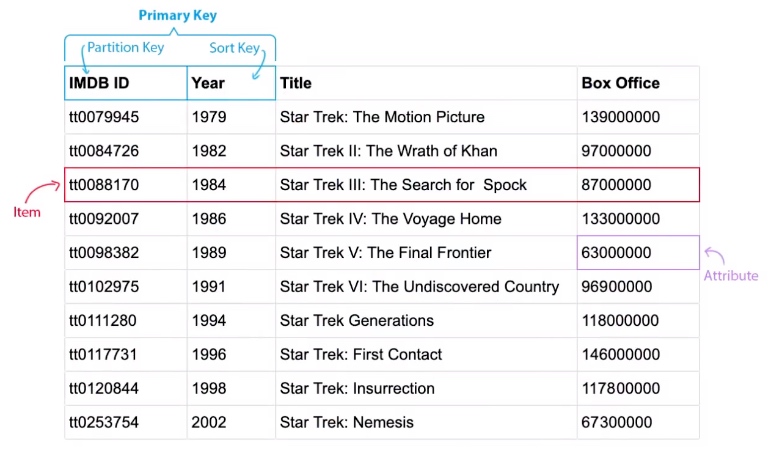
DynamoDB - Table Structure
DynamoDB - Reads

DynamoDB CheatSheet
- DynamoDB is a fully managed NoSQL key/value and document database.
- Applications that contain large amounts of data but require predictable read and write performance while scaling is a good fit for DynamoDB.
- DynamoDB scales with whatever read and write capacity you specific per second.
- DynamoDB can be set to have Eventually Consistent Reads (default) and Strongly Consistent Reads.
- Eventually consistent reads data is returned immediately but data can be inconsistent. Copies of data will be generally consistent in 1 second.
- Strongly Consistent Reads will wait until data in consistent. Data will never be inconsistent but latency will be higher. Copies of data will be consistent with a guarantee of l second.
- DynamoDB stores 3 copies of data on SSD drives across 3 regions.